Memory
The core power of Codebase Intelligence is its ability to learn and remember. This page explains how the Memory Engine works and how it integrates with your existing tools.
The Memory Lifecycle
Section titled “The Memory Lifecycle”- Observation: An event occurs (a bug is fixed, a decision is made)
- Capture: The event is captured either automatically via hooks or manually through the dashboard
- Storage: The observation is stored in the Activity Log (SQLite) and embedded into the Vector Store (ChromaDB)
- Recall: When a future task matches the semantic context of the memory, it is proactively retrieved and injected into the agent’s prompt
- Resolution: When the observation is no longer relevant (the bug was fixed, the gotcha was addressed), it is marked as resolved or superseded — either automatically or by an agent
Memory Types
Section titled “Memory Types”| Type | Description | Example |
|---|---|---|
gotcha | Non-obvious behaviors or warnings | ”The API requires basic auth, not bearer token.” |
decision | Architectural or design choices | ”We use polling instead of websockets for stability.” |
bug_fix | Solutions to specific errors | ”Fixed race condition in transaction handler.” |
discovery | Facts learned about the codebase | ”The user table is sharded by region.” |
trade_off | Trade-offs made and their rationale | ”Sacrificed write throughput for read latency.” |
session_summary | High-level summary of a coding session | ”Implemented user login flow.” |
Observation Status
Section titled “Observation Status”Every observation has a lifecycle status:
| Status | Description |
|---|---|
active | Current and relevant. This is the default for all new observations. Active observations are injected into agent context and returned by search. |
resolved | The issue was addressed in a later session. Resolved observations are hidden from default search results but preserved for historical context. |
superseded | Replaced by a newer, more accurate observation. The superseded_by field links to the replacement. |
Only active observations are injected into agent context and returned by default searches. Use include_resolved=true in search queries or the --include-resolved CLI flag to see resolved/superseded observations.
Session Origin Types
Section titled “Session Origin Types”Observations are tagged with the type of session that created them:
| Origin Type | Description | Importance Cap |
|---|---|---|
planning | Planning-phase session (mostly reads, few edits) | Capped at 5 |
investigation | Exploration/debugging session (many reads, minimal edits) | Capped at 5 |
implementation | Active coding session (significant file modifications) | No cap |
mixed | Combined activity patterns | No cap |
Session origin type is computed deterministically from read/edit ratios in the session stats — no LLM involved. Planning and investigation observations are automatically capped at importance 5 because they tend to describe temporary state (“this file is too long”) rather than permanent insights.
Auto-Resolve (Automatic Supersession)
Section titled “Auto-Resolve (Automatic Supersession)”When a new observation is stored — whether extracted automatically from a session or stored explicitly via oak_remember — the system checks for older observations it might replace.
How it works
Section titled “How it works”- Search: ChromaDB is queried for the top 5 semantically similar active observations of the same memory type (e.g., gotcha→gotcha, not gotcha→discovery)
- Threshold check: Each candidate is compared against a similarity threshold:
- Same file/context (both observations reference the same file path) → 0.85 cosine similarity
- No shared context → 0.92 (stricter to avoid false positives)
- Supersede: Observations above the threshold are marked
supersededwith a link back to the new observation viasuperseded_by - Dual write: Both SQLite (source of truth) and ChromaDB (search index) are updated
What determines similarity?
Section titled “What determines similarity?”Similarity scores come from cosine distance between embedding vectors in ChromaDB. The configured embedding model (e.g., nomic-embed-text) converts observation text into high-dimensional vectors. A better embedding model produces more semantically meaningful similarity scores.
What’s skipped
Section titled “What’s skipped”session_summaryobservations are never auto-resolved (they use deterministic IDs and upsert naturally)- Same-session observations are skipped (can’t supersede yourself)
- Observations below the threshold are left alone — false positives are worse than missed resolutions
Example
Section titled “Example”A planning session produces: “constants.ts is 800 lines and should be split into domain modules” (gotcha, context: src/lib/constants.ts).
A later implementation session completes the refactoring. The LLM extracts: “constants.ts was refactored into domain modules under lib/constants/” (gotcha, context: src/lib/constants.ts).
Same type (gotcha), same file context, similarity well above 0.85 → the old observation is automatically superseded. Future agents no longer see the stale “should be split” advice.
Manual Resolution
Section titled “Manual Resolution”Agents can also resolve observations explicitly when they complete work that addresses a known issue:
- MCP tool:
oak_resolve_memory(id="<observation-id>", status="resolved") - CLI:
oak ci resolve <observation-id> - Bulk by session:
oak ci resolve --session <session-id>
Observation IDs are included in injected context and search results, so agents have what they need to call oak_resolve_memory without extra lookups.
Auto-Capture Hooks
Section titled “Auto-Capture Hooks”OAK CI automatically installs hooks into supported agents during oak init. No manual configuration is required.
Supported Integrations
Section titled “Supported Integrations”| Agent | Capability | Integration Method |
|---|---|---|
| Claude Code | Full (Input/Output Analysis) | settings.json hook scripts (auto-synced) |
| Codex CLI | Partial (Output Analysis) | OTLP log events & Notify |
| Cursor | Full (Input/Output Analysis) | .cursor/hooks.json (auto-synced) |
| Gemini CLI | Full (Input/Output Analysis) | settings.json hook scripts (auto-synced) |
| OpenCode | Partial (Output Analysis) | TypeScript plugin (auto-installed) |
| VS Code Copilot | Full (Input/Output Analysis) | .github/hooks/hooks.json (auto-synced) |
| Windsurf | Partial (Output Analysis) | .windsurf/hooks.json (auto-synced) |
| MCP Agents | Tools + Context | Auto-registered MCP Server |
Post-Tool Analysis
Section titled “Post-Tool Analysis”When using fully supported agents (Claude/Gemini), the CI daemon analyzes every tool output (e.g., Bash, Edit, Write).
- Error Detection: If a command fails, it records the error as a
gotcha - Fix Detection: If you
Edita file after an error, it correlates the fix with the error and stores abug_fix - Summarization: At the end of a session, a local LLM summarizes the work and updates the project memory
Managing Memories
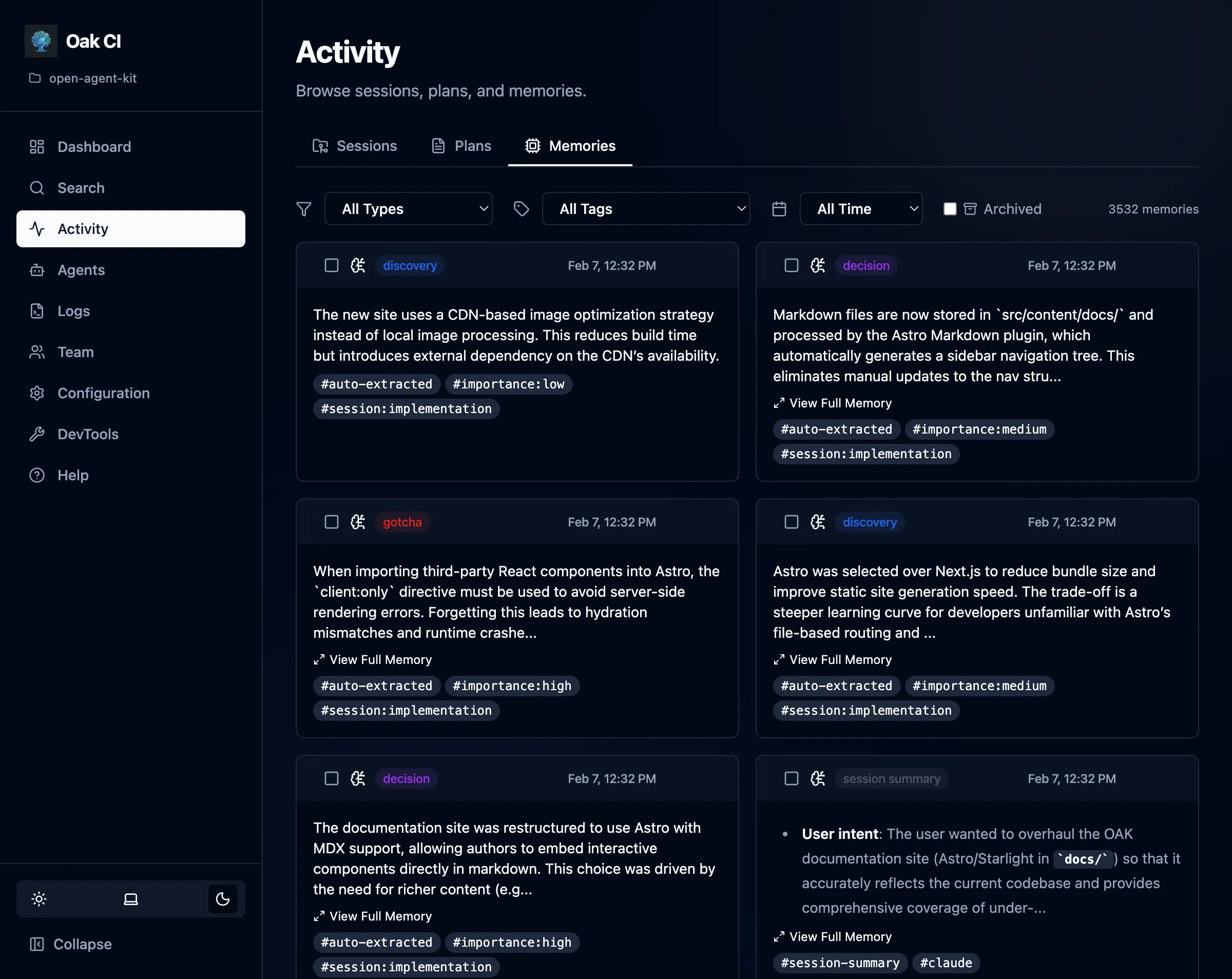
Section titled “Managing Memories”The dashboard is the primary way to manage memories. Open the Activity > Memories tab to:
- Browse all stored memories by type, date, status, or content
- Search memories using natural language queries
- Archive memories to hide them from active lists (reversible)
- Delete memories that are outdated or incorrect
Agents can also store memories programmatically using the MCP tools. See MCP Tools for details on oak_remember and oak_resolve_memory.
Rebuilding Memory Embeddings
Section titled “Rebuilding Memory Embeddings”If you change embedding models, rebuild the memory index from the dashboard’s DevTools page — click Rebuild Memories to re-embed all observations from SQLite into ChromaDB.
Agent Hooks API
Section titled “Agent Hooks API”If you are building your own tools or agent integrations, you can hit the hook endpoints directly:
POST /api/oak/ci/hooks/session/start{ "agent": "custom-agent", "project_path": "/path/to/project"}See the API Reference for more details.